

Con motivo del inicio del curso escolar y, por qué negarlo, cargado de nostalgia, quiero recordar de nuevo este post en el que cuento uno de los días de mi experiencia como maestro de escuela en Nepal en el año 2007 durante unas intensas vacaciones. Enseñar a estos chavales te reconcilia con la raza humana y se lo quiero dedicar a los profesores que este año las van a pasar más crudas que de costumbre ante la escasez de personal y el incremento de alumnos por aula.
Los enlaces al resto de los posts que escribí relatando esta experiencia docente son estoss:
Este es el impresionante vídeo en HD generado a partir de 568 imágenes tomadas por una de las cámaras del Mars Curiosity Rover según descendía.
El pasado 31 de Julio impartí el curso "Twitter: usos educativos y sociales de la conversación efímera" en el Instituto de Tecnologías Educativas y de Formación del Profesorado en Madrid a los mismos alumnos a los que impartí el curso "Blogs, blogosfera y cultura hacker" que ya he referenciado en este post. Esta coincidencia de asistentes me permitió comparar los blogs con lo que se ha dado en llamar "microblogging" y llegando a la conclusión de que la diferencia entre un blog y lo que sucede en Twitter es de mucho más calado que simplemente una diferencia de tamaño en los posts. La diferencia está entre considerar a Internet una interconexión de información personal mediante técnicas o considerarla un parque temático de jardines amurallados que nos ofrecen servicios y a cambio se quedan con nuestros datos personales para hacer dinero con ellos. Y mucho dinero.
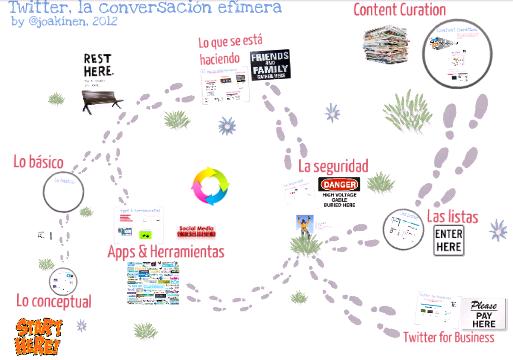
La figura del Community Manager está sobrecargada de significados. Le sucede un poco como al término "informático", que en España viene a significar desde el "manitas" que te repara el ordenador hasta el arquitecto de bases de datos. Veo algo parecido en el Community Manager, cuyas competencias deberán fragmentarse en diversas especialidades no pasando mucho tiempo.
Tratando de entender yo mismo las diferentes especialidades que intervienen en la presencia de cualquier proyecto en las redes sociales hice este pequeño gráfico que más que explicar, refleja lo difícil que es delimitar especialidades. Tómalo como un ejercicio personal para tratar de aclararme, no como explicación de nada.
Esta es la presentación usada en 2012 para el curso de usos básicos de las redes sociales y herramientas de apoyo.
La presentación está hecha en Prezi y puedes verla aquí mismo.
La siguiente presentación corresponde al curso "El papel del blog en la conversación 2.0 - La blogosfera y la cultura blogger" presentado en el Instituto Nacional de Tecnologías Educativas y de Formación del Profesorado.
La presentación está hecha en Prezi y puede verla aquí mismo.
El pasado 29 de Mayo de 2012 asistí al Seminario Internacional Redes Sociales, Educación Mediática y Aprendizaje Digital celebrado en la Facultad de Ciencias Económicas y Empresariales de la UNED en Madrid. Hacía tiempo que no escuchaba juntas tantas ideas innovadoras sobre cómo usar las nuevas herramientas sociales en el campo de la educación (y por extensión en el de la divulgación). Como vengo haciendo últimamente, tomé notas en forma de tuits de aquellas frases que me parecieran sugerentes o sobre aquellos temas que me interesa explorar.
He hecho aquí una recopilación de los tuits que escribí para crear una nueva oportunidad de comentarlos, retuitearlos, discutirlos o simplemente leerlos.
Estos son los últimos tuits que he escrito estos últimos días.
Una oportunidad más para contestarlos o comentarlos y así continuar la conversación.
Estos son los últimos tuits que he escrito estos últimos días.
Una oportunidad más para contestarlos o comentarlos y así continuar la conversación.
Ayer pudimos asistir mediante varias redes sociales a un extraordinario evento: la retransmisión en directo de una operación quirúrgica que consistía en la extirpación de un tumor cerebral a una paciente de 21 años.
La intervención la llevó a cabo el neurocirujano Dong Kim. Un colega suyo con un ordenador portatil escribía la narración del evento en Twitter, una videocámara instalada sobre la mesa de operaciones grababa fragmentos de vídeo en ocasiones relevantes y un fotógrafo tomaba fotografías digitales.
Tomando como punto de partida la aparición en 1999 del Manifiesto Cluetrain y su tesis de que "Los mercados son conversaciones", Alberto Ortiz de Zárate construye un potente argumento que se desarrolla a través de las algo más de 100 páginas de su libro "Manual de uso del blog en la empresa. Cómo prosperar en la sociedad de la conversación": Internet no es un medio de comunicación masiva, es el escenario de una conversación global a la que se deben de sumar las empresas, para lo cual es posible que tengan que transformar sus estrategias de comunicación en esfuerzos por conversar en un plano de igualdad con sus clientes y conseguir interesar con sus propuestas.
Estos son los últimos tuits que he escrito esta semana.
Una oportunidad más para contestarlos o comentarlos y así continuar la conversación.
Ayer estuve en el concierto inaugural en RetroMadrid 2012 en la nave 16 del Matadero Madrid. Fue una delicia mezclar la música sinfónica con las imágenes de 8 bits.
A la hora de comienzo del concierto llovía torrencialmente en Madrid y buscar la nave 16 en el enorme y laberíntico Centro Cultural Matadero con las prisas de llegar tarde y empapándome no fue tarea fácil. Deberían de mejorar la señalización, poner alguna indicación de cómo llegar a cada nave, ya que solo ves el número de la nave cuando estás delante de la puerta.
Estos son los últimos tuits que he escrito esta semana.
Una oportunidad más para contestarlos o comentarlos y así continuar la conversación.
Los pasados 22, 23 y 24 Marzo de 2012 se celebró en Madrid el XII Foro de Tendencias Sociales titulado "Nuevos Problemas Sociales", organizado por el Grupo de Estudio sobre Tendencias Sociales, un grupo de investigación fundado en el año 1995 bajo el patrocinio de la UNED (Universidad Nacional de Educación a Distancia), la Fundación Sistema y la Universidad de Alicante con el objetivo de elaborar investigaciones empíricas sobre asuntos tales como las desigualdades y los procesos de exclusión, los problemas sociales, las oportunidades económicas y sociales de las nuevas tecnologías, la influencia de Internet en las familias y los efectos de la revolución tecnológica, entre otros.
Cada uno de los once foros anteriores se ha centrado monográficamente en un escenario o tendencia social, siendo estos los celebrados hasta la fecha:
Estos son los últimos tuits que he escrito esta semana.
Una oportunidad más para contestarlos o comentarlos y así continuar la conversación.
Ustream.tv es un servicio de Internet mediante el cual podremos crear canales de vídeo para emitir eventos en directo de forma gratuita. Las opciones que nos ofrece Ustream desde su página son suficientes para una transmisión "casera" de un evento, pero si queremos transmitir con más calidad necesitamos hacer algunas cosas extra que enumero en este post. La técnica usada sirve tanto para máquinas Windows o Mac OS.
Por supuesto, necesitaremos abrirnos una cuenta gratuita en Ustream y abrir un canal de emisión. No es necesario abrir diferentes cuentas para emitir contenidos de diferente tipo, sino que podemos abrir varios "canales" y usar cada canal para todas las retransmisiones de un mismo evento. Ustream permite a los usuarios que quieran ver eventos en directo suscribirse a canales concretos por lo que si separamos nuestras transmisiones por temas y cada tema lo transmitimos siempre por el mismo canal facilitamos mucho que se sigan nuestros vídeos.
En la página de Russ Cox sobre programación, este genial programador que ahora trabaja para Google y allí desarrolla el lenguaje de programación Go ha publicado dos artículos en los que analiza las matemáticas que hay tras los códigos QR y como consecuencia de sus investigaciones, ha conseguido programar la posibilidad de incluir una foto nuestra como parte de la imagen QR.

La agencia de investigación y consultoría estratégica The Cocktail Analysis publicó la semana pasada su Cuarta Oleada de El Observatorio de Redes Sociales, continuando el trabajo que han venido haciendo desde 2008 cuando, a pesar de ser un fenómeno emergente, inician un Obervatorio de Redes Sociales lanzando una primera oleada de resultados.
El informe presenta los resultados de una encuesta online realizada en Diciembre de 2011 a 1304 internautas de entre 16 y 45 años, seguido de 26 entrevistas en profundidad (de 90 minutos de duración) y contiene tanto una panorámica general de la evolución de la pertenencia y hábitos de uso como secciones temáticas sobre hábitos específicos. Precisamente una de esas secciones trata, a partir de la diapositiva 42, sobre la percepción de la presencia de marcas en las redes sociales.
Estos son los últimos tuits que he escrito esta semana.
Una oportunidad más para contestarlos o comentarlos y así continuar la conversación.
Otras entradas:
/ (134)
[repost] Clase inesperada a los chavales de Grade 4 07/09/2012El aterrizaje de Curiosity en HD 20/08/2012
Twitter: para qué sirve la conversación efímera 16/08/2012
Despiezando al Community Manager 26/06/2012
Curso: Uso básico de las redes Sociales 26/06/2012
Curso: Blogs, blogosfera y cultura blogger 18/06/2012
Mi resumen del #MasterRedesUned 01/06/2012
Resumen de la semana en Twitter 25/05/2012
Resumen de la semana en Twitter 14/05/2012
Un ejemplo de divulgación científica en redes sociales 10/05/2012
Últimos cursos
cursos (13)
Twitter: para qué sirve la conversación efímera 16/08/2012Curso: Uso básico de las redes Sociales 26/06/2012
Curso: Blogs, blogosfera y cultura blogger 18/06/2012
El marketing empresarial en las redes sociales 10/04/2012
Redes Sociales y Divulgación de la Ciencia 19/10/2011
Redes Sociales y Divulgación de la Ciencia 28/06/2011
Curso sobre Redes Sociales #crs11 01/06/2011
Qvo Vadis Internet 27/05/2011
Curso de herramientas para gestión de presencia online 25/05/2011
Curso "Sistemas Operativos y Seguridad" 24/05/2011
Categorías
- astrocosmo (1)
- calculadoras (2)
- citrix (2)
- communitymanager (1)
- cts (1)
- cursos (13)
- databases (0)
- diseno (1)
- educacion (8)
- etc (4)
- ethernet (1)
- google (1)
- internet (5)
- investigacion (1)
- mma (1)
- musica (1)
- nepal (24)
- networking (1)
- noticias (0)
- openbsd (0)
- programacion (3)
- quintinracionero (1)
- redes_sociales (5)
- scratch (1)
- scripts (2)
- seguridad (7)
- sistemas (12)
- sistemas: mainframes (0)
- sistemas: minicomputers (0)
- sistemas: psion (0)
- sistemas: retro (1)
- sociedad (1)
- spanishrevolution (5)
- tecnologia (4)
- twitter (9)
- web20 (15)





